Main Textflo Application

This is the 'main application', but it might not be used as frequently as the Organiser. It can read Text, XML, PDF, HTML, or even Binary files and apply a sequence of operations to transform or filter the text. The transformation can involve removing or changing text parts, as specified by a filter procedure that can then be saved and re-used. Another panel provides a grid format for viewing the text as cells, or for database queries, while a third panel provides a set of analysis features, either for a single document or document comparisons.
Textflo Panels
The main Textflo product consists of three main panels. The text-processing functionality can be described through these panels, where two of the panels can filter or format the text, while the third panel can perform a limited amount of analysis over the text. This can be very useful for difficult operations that you might not typically perform.
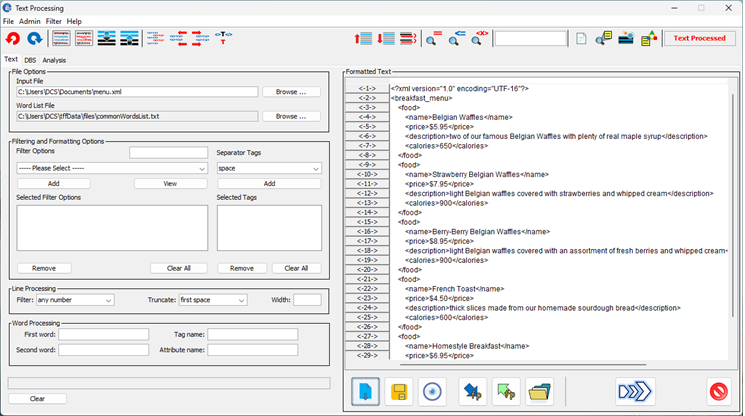
| 1. Text Panel |
Allows for general filtering operations over the whole text file. This can process any of the text formats to produce radically different content, as defined by the user, in just a few operations. Search operations also allow you to find content very quickly. |
|
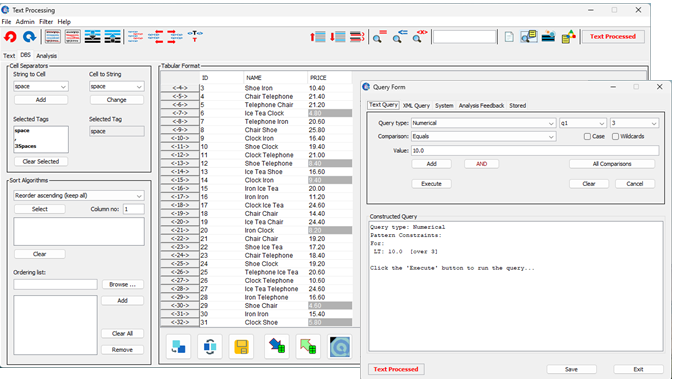
| 2. DBS Panel
|
Allows the user to view database queries, or manually change specific areas of the text. With a tabular format, complex sorts and queries over rows or columns of data are also possible. |
|
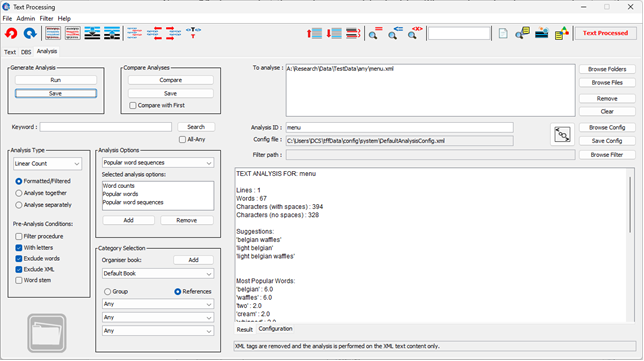
| 3. Analysis Panel
|
Can perform some statistical analysis over the raw or filtered text. This is now very flexible with regard to what text to analyse and what file groups to combine or cluster. It can help with understanding what the text is about or related texts and links up with the Organiser. |
|
Product Details
The Textflo panels are described in slightly more detail here:
Text Panel
This panel can perform filtering and formatting processes over the whole text document and is shown below. You specify a number of filtering/formatting options that are to be performed in sequence and then run them to change the text. The procedure can even be saved to a file and then re-loaded, to make document processing easier. This panel consists of a left-hand side with the filtering/formatting options and a right-hand side that shows the document after it has been changed.
You can reformat the whole document, or select specific sections that will be reformatted by themselves. You can also perform a number of queries over the text, where matching results will be highlighed and can then be moved to.
DBS Panel
You can connect to a database using HyperSQL and view query results in the Database and Sorts panel. Also, while the Text panel allows you to choose a sequence of operations that are automatically applied to the whole document, or document sections. This panel provides additional functionality through a grid or tabular format that allows you to select specific columns and rows to delete or change. Although this is slightly unusual, the tabular format also allows for complex sorts, or even queries, over specific columns of data. So with the grid format you can:
- View database tables.
- Re-format by removing (whole or partial) columns or rows of data. Insert new columns, or alter the text in existing cells.
- Parse or save text in a tabular structure, with user-specified separators between the cells, such as for a CSV file.
- Perform sorts or queries over 'specific columns' of data. For a table, for example, you can sort or query data in the middle of the table, as you might do with a database.
Analysis Panel
The product also comes with a panel that can provide a limited amount of analysis over groups of text documents, including re-formatted text from the Text panel. The analysis can provide statistical count or frequency values, for words or word sequences. It can also use known clustering algorithms to group sets of documents. There are a number of algorithms, where the analysis includes:
- The standard line, word and character counts of a Word Processor, for example.
- Other frequency counts, including the most popular words or word sequences.
- Feedback to highlight lines in the main text that contain popular word sequences.
- Clustering over the frequency analyses or document content, including comparisons with the category groups stored as part of the Organiser application. You could then use the clustering to re-categorise, for example.
The analysis can be performed over the previously filtered text, or the text from a number of files, either combined or separate. It is configurable and can be saved in XML format, where several different analysis sets can then be compared. Optional analysis features also allow you to remove numbers, symbols, or commonly occurring words, during a pre-processing stage.
Analysis Details Document
The more technical details of what is analysed, has been moved to a separate document that can be downloaded from here. You can still use the application and get a feel for an analysis setup that works well, or you can read more about the algorithms in the document.