Licas Server
The framework comes with a server for running the services on, mechanisms for adding the services to the server, mechanisms for linking services with each other, and mechanisms for allowing the services to communicate with each other. The default communication protocol inside of licas itself is an XML-RPC mechanism, but REST-style messages can also be processed and Web Services invocation is also possible. The system is able to automatically decide on the message type and convert it accordingly. The system also provides an implementation of an Autonomic framework, including the 'model-analyze-plan-execute' loop, behaviours and policy scripts. Only the framework is provided however, where the user would be expected to write actual implementations of the main components. Services are protected with passwords, where this can be one password for the whole service, or through a script, passwords can be set for different access levels and methods. There is also some basic search and metadata processing capabilities.
1. Network Structure and Communication Protocols
The system is designed to be peer-to-peer (p2p), where any service can both send (client) and receive (server) messages from any other service. Any remote message that is recieved, firstly passes through the base server, before being directed to the service that it is addressed to. The same communication process can also allow for direct invocation on an Object reference. Figure 1 shows the general architecture of what a distributed network would look like..
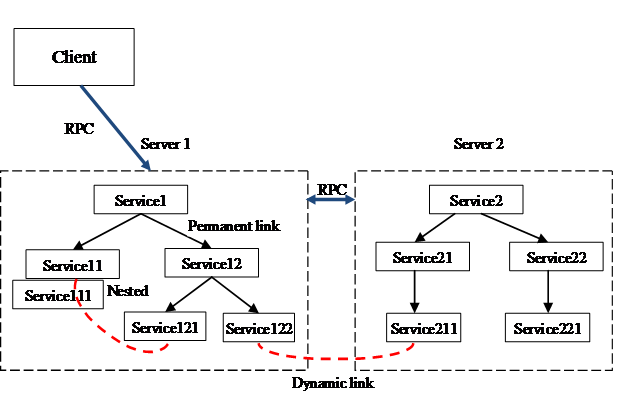
Figure 1. Example of two Licas servers running service networks.
This diagram shows two servers running two different networks of services. The services can be structured in either network by permanent links, represented by the solid black arrows. Some services may have created dynamic links between each other, represented by the dashed red lines. The dynamic links can cross over networks as well. The server is more of an application server than a web server, where the services provide most of the functionality. Figure 2 shows the different communication protocols.
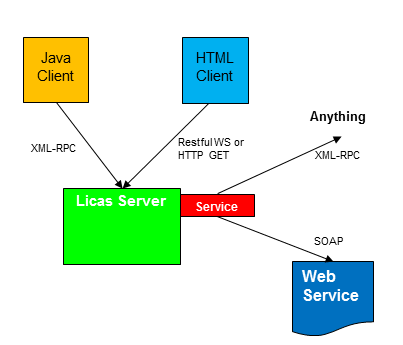
Figure 2. Example showing the different types of communication.
So internal communication in the licas system is by XML-RPC or direct reference, where service communication is done at the level of invoking a method on another service. A client can use either XML-RPC or RESTful-style messages to invoke a service running on a server, and either a client or a service can call an external Web Service or HTTP URIs dynamically, also through the licas classes.
2. Modular Architecture
The framework can be broken down into several modules, where not all of them might be required for a system. At the lowest level is a Service class. If you extend this with your own class, then you can add your own service to a network with all of the required licas functionality. Or there is now a lighter ServiceModule class. The Auto class extends the Service class and provides for agent-like communications or continuous behaviours. Ontop of this there is the possibility for adding metadata to describe the service. All of the metadata is in XML format. The metadata can also be used to describe different security levels. Figure 3 shows the modular architecture.
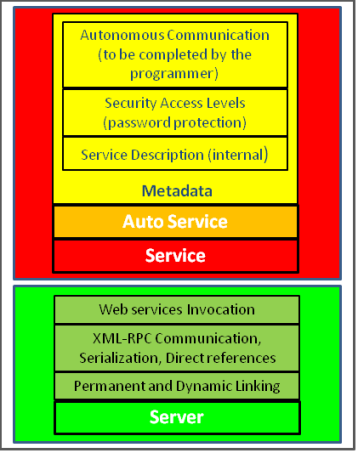
Figure 3. Modular architecture of the licas system. The server and service modules are shown.
The server modules are shown in green. The HTTP server can manage metadata, linking and communication mechanisms. The dynamic linking mechanism is provided as a utility 'Link' service or module, that you add to your own service and invoke, where there are built-in meshanisms for doing this. If passing complex Java objects, then you need to write a parser for those classes, but the basic types are parsed as default. Alternatively, you can also serialize your objects, or local calls can use direct references. You can also load in your own class that is not derived from licas at all. It will be stored in a Wrapper before being loaded onto the network, where the wrapper provides most of the essential functionality.
3. Autonomic Computing
The system also protects any service with by a wrapper object.
This makes it difficult to obtain a direct reference without
the correct password. This wrapper is a 'ServiceWrapper' by default,
or if the service is derived from 'Auto', it is an
'AutonomicManager' wrapper. The default autonomic manager allows
the service to operate as normal and also provides a message queue for
messages that the service receives. It calculates some server-level
stats, such as number of calls, but does not do any monitoring.
The autonomic manager is made up of monitor, analyse, plan
and execute modules that can be used to monitor the service in question and
take action when there is a fault. Because this sort of activity is
very application specific, it cannot be programmed completely and also
lies outside of the scope of licas. Therefore, only a framework is in
place to allow these modules to be loaded and work together. In the
licas system, only the base service has an Autonomic Manager. Any
service that is nested inside of any other service is taken to be a
utility service to the base service and is not monitored at all. The
framework that is in place should be helpful and it would be worth looking at the code to see how it works if you are
going to implement these modules yourself. Figure 4 shows the basic
architecture of the autonomic manager. Note that the licas Service
class now also has a contract manager for processing contract
proposals for its service. These would be related to the stored
metadata.
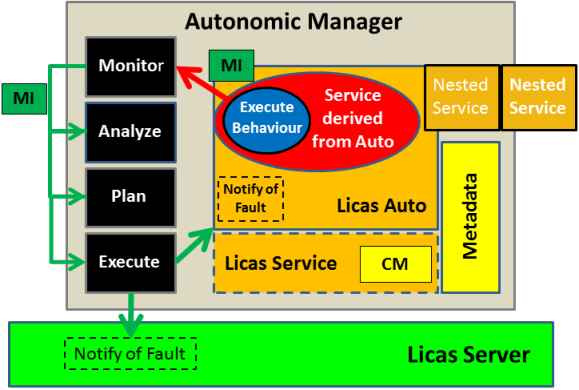
Figure 4. Autonomic Manager wrapper with stored object.
4. Problem Solving
The system can be used to execute distributed services, where those features are also integrated with a centralised problem solver. The default package provides some new clustering algorithms as well. One test option therefore, is to start a group of distributed services running that would autonomously interact with each other. The other option is to manage the AI in a more centralised component, where the services send their data to it. The framework can also be used simply as a general problem solving environment, without considering services or networks; but it would then have a more limited functionality. It is worth looking at the ‘ai_heuristic’ javadocs to see what algorithms are provided as default.
Figure 5 shows the basic architecture of the problem solver. An information mediator can be used to receive the information from the distributed sources. This is then sent to the problem solver which creates solutions of the specified type and clusters the sources, or solves the problem, as best it can. The resulting clusters can then be turned into dynamic links and used to update the network structure, for example. The information mediator can communicate directly with the services running on a network and the results viewed in the GUI.
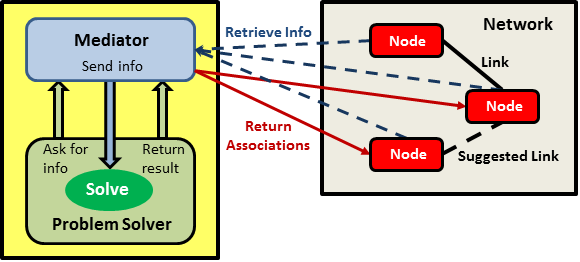
Figure 5. Problem Solving Architecture for Organising Information Sources.